
Dne 21. listopadu byl uveden Stable Video Diffusion. Jedná se o pozoruhodný model generativní umělé inteligence (AI) pro video, který vychází ze svého předchůdce – modelu obrazů Stable Diffusion. Tento pokrok reprezentuje významné rozšíření portfolia aplikací AI, přičemž Stable Video Diffusion nabízí nevídanou kvalitu zdánlivě překonávající i současného monopolního giganta Runway.
Inovativní Přístup ke Generování Videí
Stable Video Diffusion, který nyní zdobí stránky GitHubu, nabízí jedinečný kód, jenž umožňuje uživatelům spustit model lokálně. Tato možnost je podrobně popsána na webu Hugging Face. Pro ty, kteří touží po hlubším ponoru do technických aspektů, je k dispozici výzkumná práce nazvaná „Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets“ od Stability AI, která přináší ucelený vhled do schopností a potenciálu modelu: stabilityai/stable-video-diffusion-img2vid-xt · Hugging Face
Adaptace pro Široké Spektrum Aplikací
Stable Video Diffusion se vyznačuje vysokou mírou adaptability, což umožňuje jeho aplikaci v různých oblastech. Například je schopen provádět multi-view syntézu z jediného obrázku, což se dosahuje díky jemnému doladění na multi-view datasetech.
Multi-view syntéza: Jak to funguje?
V kontextu technologie Stable Video Diffusion, když se hovoří o schopnosti provádět multi-view syntézu z jediného obrázku, máme na mysli pokročilý proces, kde model umělé inteligence (AI) je schopen generovat reprezentaci objektu nebo scény z různých perspektiv na základě jediného statického obrázku. Tato schopnost je získána díky tzv. „jemnému doladění“ modelu na multi-view datasetech. Jak to ale funguje?
- Trénování AI Modelu: Nejdříve je model AI trénován na multi-view datasetech, které obsahují obrazy nebo data stejného objektu či scény z různých úhlů. Toto trénování umožňuje modelu lépe porozumět, jak se objekty mění v závislosti na perspektivě.
- Syntéza z Jednoho Obrázku: Po trénování na těchto datech je model schopen aplikovat získané znalosti na jediný obrázek. Tímto způsobem dokáže odvodit, jak by daný objekt nebo scéna vypadal z různých úhlů, i když má k dispozici pouze jeden pohled.
- Jemné Doladění: Jemné doladění se týká procesu úpravy a optimalizace modelu, aby jeho výstupy byly co nejpřesnější a nejrealističtější. V kontextu multi-view syntézy to znamená upravit model tak, aby co nejlépe interpretoval různé perspektivy založené na omezeném množství vstupních dat (v tomto případě jediný obrázek).
- Praktické Aplikace: Takovýto přístup má široké využití, například ve 3D modelování, kde by mohlo být možné vytvořit komplexní 3D modely pouze z několika fotografií, nebo v rozšířené realitě, kde by mohly být objekty rekonstruovány a virtuálně umístěny do reálného světa s vysokou úrovní detailu a přesnosti.

Obrázek 1 – Ukázky Stable Video Diffusion na Hugging Face
Předběžný přístup
Pro ty, kteří chtějí být u zrodu nové éry videí, je nyní otevřená možnost zápisu na čekací listinu. Tím získáte přístup k novému webovému rozhraní s Text-To-Video funkcí, demonstrující praktické využití Stable Video Diffusion napříč různými odvětvími.
Výkonnostní Přednosti Modelu
Stable Video Diffusion nabízí modely schopné generovat video se 14 či 25 snímky za sekundu (FPS), s možností nastavení frekvence snímkování. Tyto modely se ve studiích uživatelských preferencí již nyní umístily nad konkurenční uzavřené modely, což nejspíše svědčí o jejich mimořádné výkonnosti.
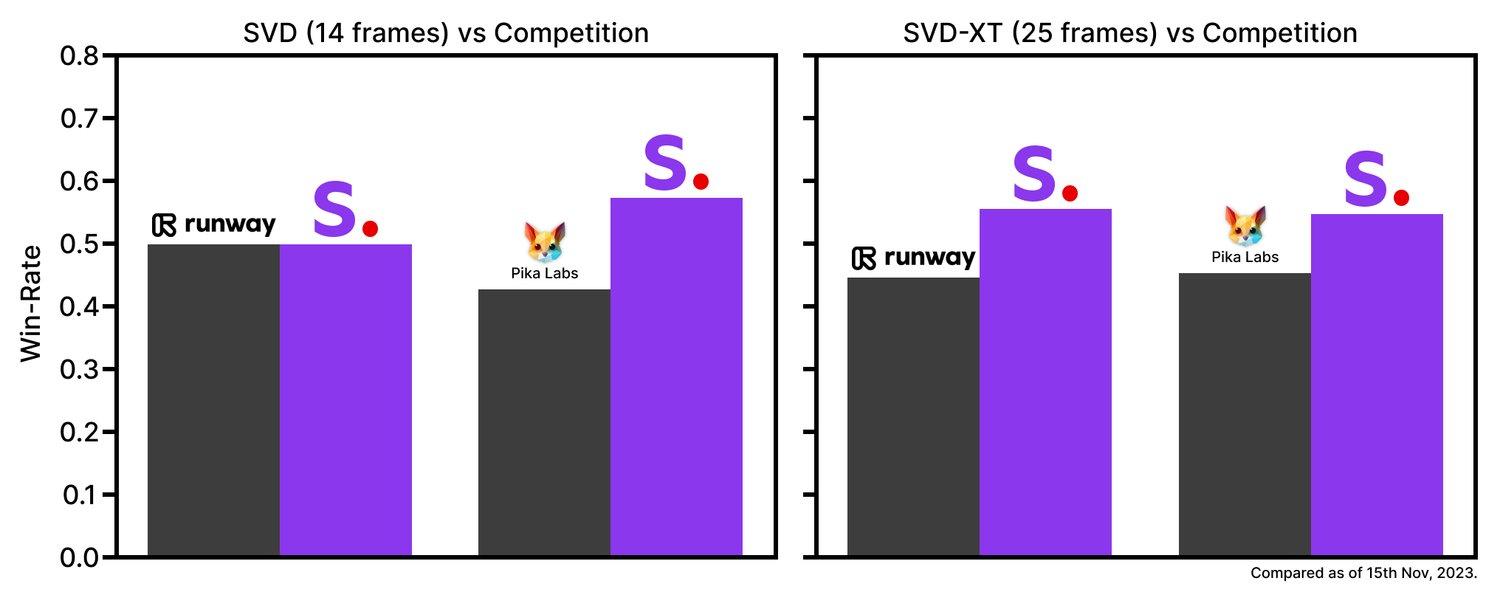
Obrázek 2 – Porovnání modelů pro generování videa z obrázku
Exkluzivita Pro Výzkumné Účely
V současné době je Stable Video Diffusion primárně zaměřen na výzkumnou sféru. Prozatím se vývojáři snaží získat zpětnou vazbu, na základě, níž budou moci model inovovat a zdokonalovat. Poté je možné předpokládat, že se model rozšíří i pro komerční využití.
Rozšiřující se Portfolio AI Modelů
Stable Video Diffusion je nejnovějším přírůstkem k portfoliu open-source modelů společnosti Stable Diffusion, které zahrnují široké spektrum oblastí – od obrazů, přes jazyk, audio a 3D, až po kódování. Společnost se tím tak snaží jít napřed inovacím a vytvářet silnou konkurenci svým oponentům, včetně Midjourney nebo platformy Runway, která až doteď zaujímala monopol se svým GEN-2 modelem pro tvorby videa z obrázku či textového příkazu. To se ale nyní může změnit.
Shrnutí:
- Stable Video Diffusion představuje významný pokrok v oblasti generativní AI pro video.
- Model je zdarma s kódem dostupným na platformě GitHub, což umožňuje široké využití a adaptaci.
- Model nabízí možnosti aplikace v různých sektorech, od vzdělávání po zábavu. V současnosti je ale spíše určen pro vědeckou sféru.
- Výkonnost modelu byla ověřena uživatelskými studiemi a je exkluzivně určena prozatím pro výzkumné účely.
Zdroj:
- Islamovic, A. (2023, November 21). Introducing stable video diffusion. Stability AI. https://stability.ai/news/stable-video-diffusion-open-ai-video-model?ref=futuretools.io







{kind=link}